Merkle Tree: The Root of Bitcoin
Why Merkle Tree is used in Blockchain

All programmers would agree on how important Data-structures and Algorithms are. And Trees are one of the most important data structures among them. The funny thing about Trees in Computer Science is that their roots are at the top (looks like an upside-down tree). But what is a Merkle Tree? How is it different from other trees?
What is a Merkle Tree?
The first-ever mention of such a tree was cited in the early 80s. This tree is named after Ralph C Merkle who published a paper on Protocols for Public Key Cryptosystems. In his paper, he referred to a tree-like data structure for verifying data integrity on a peer-to-peer (decentralized) network.
Before discussing the Merkle Tree, let’s quickly recap a few terms related to a traditional tree and hash functions.
1. A quick intro to Tree data structures
Whenever we need to represent some data hierarchically, we use trees. They are commonly used in storing folder structures, XML/HTML data, etc. An example of a tree is shown in the image below.
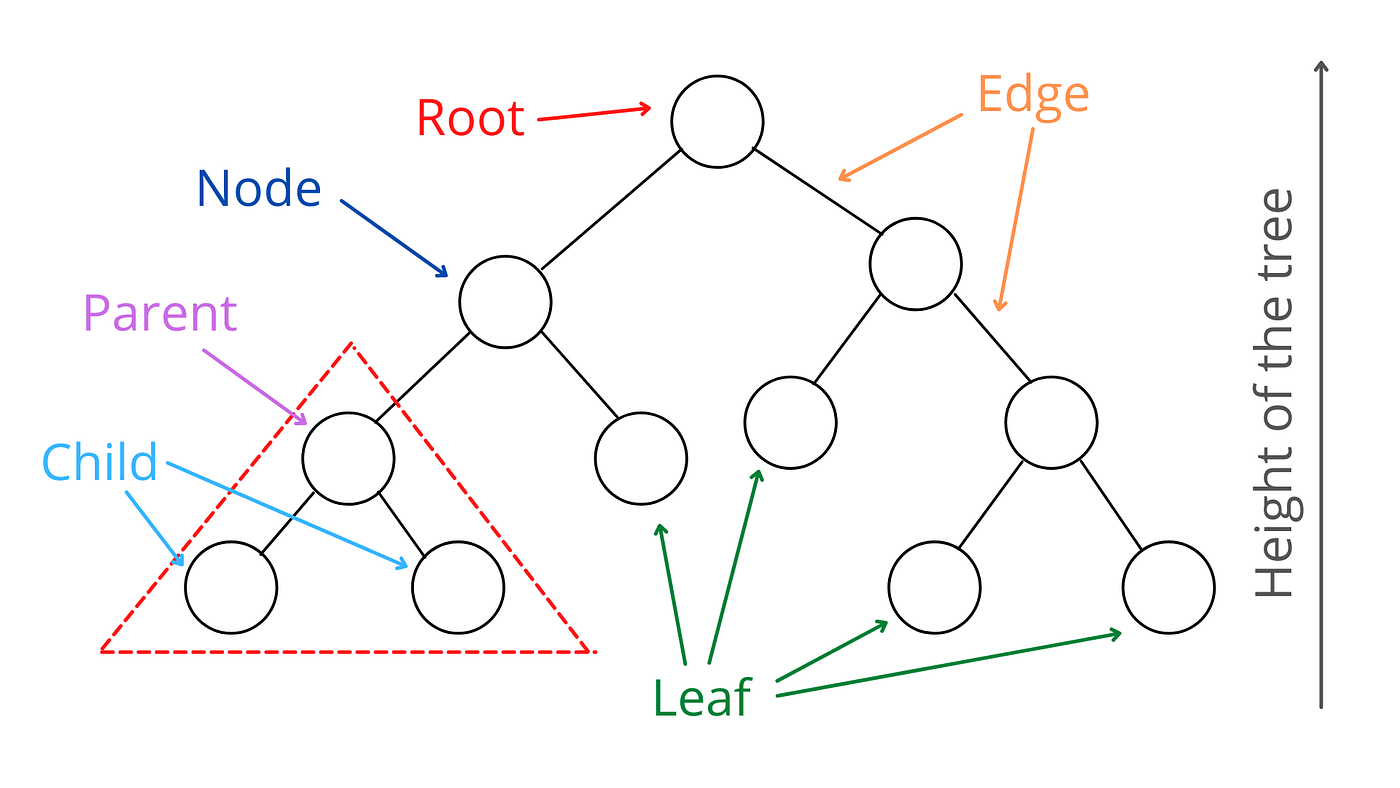
Few useful terms related to Tree:
- Nodes: Each member of a tree is called a node.
- Edge: The connecting lines between nodes are called edges.
- Root: The topmost node in the tree is called the Root of the tree. Every operation begins from the root node.
- Parents and Child nodes: Parent nodes are the nodes that have one or more nodes connected below them. The nodes below the parent nodes are called their child node.
- Leaf nodes: The bottom nodes of the tree are called leaf nodes.
2. Hash Functions
Hashing is the process of converting input data into a fixed-size output string called the hash value of the data. They consist of numbers and letters but no special characters. One benefit of using hashes is that they always consume less memory than the data represented by them.
Some important properties of Hash functions:
- They are irreversible, i.e., you cannot find the actual data from its hash value.
- A small change in the data will result in a completely different hash value.
- Identical data will always produce the same hash value. This is very important for checking data integrity since you cannot reverse the data.
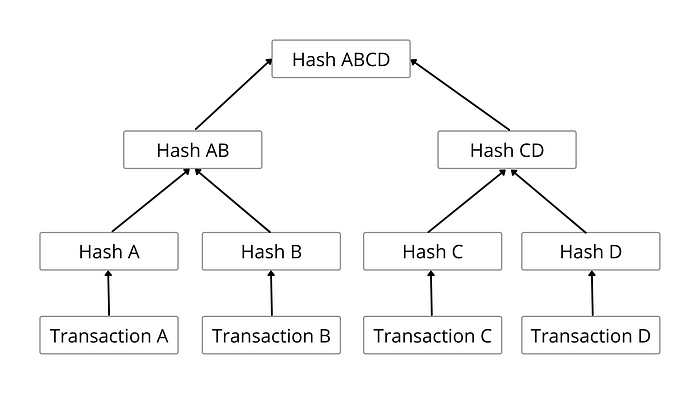
Merkle Tree
In a Merkle tree, every node represents the hash value of its children. The whole tree is constructed by using the hash value of the leaf nodes in a bottom-up approach until we get to the root.
Algorithm for constructing a Merkle Tree:
- Calculate the hash values of each data in the list.
- Group the hash values into pairs (2 hash values in a group) starting from left to right.
- Concatenate the hash values in a group and calculate its hash value.
- Repeat steps 2 & 3 until there’s only one hash value left that will be the root of the tree.
Let’s create a Merkle Tree in JavaScript
We will create the tree using a Recursive function. But first, we will define the classes for Merkle Node and Merkle Tree. A Merkle node has a value and two child nodes we will name them left and right. The node either will have both of its children or none of them.
Next, we will implement a recursive function to construct the whole tree. The function will take the child nodes as its parameter and construct their parents and then call the function again passing the parents as the child nodes until we get the last node. The last node will be the root of the Tree. We will generate the hash values using the built-in library of nodejs called crypto.
Now, we will define the Merkle Tree class. Merkle Tree will have a size and the root node. The root node contains all its children thus, making the entire tree. We will implement a static create method in the class to initiate the Tree with a given list of transactions or any data. The create method will generate the leaf nodes from the transaction list and pass them to the makeTree function to get the root of the tree. The complete code is available in this gist.
Searching in Merkle Tree
You can easily check for a transaction or data is present in the Merkle tree without traversing the entire tree. This method is called Proof of Inclusion.
Let’s say there’s a Merkle Tree of some transactions A to H. And we have access to the Merkle Root. Now we need to search whether Gexists in the tree or not. We can easily calculate the hash of transaction G. We can now re-calculate the root hash from the hash(G) by tracing the path to the root node.
How to trace the path to the root node?
For each node, we know there’s exist another pair that leads to its parent node. In the case of G, it is H, if we can get the hash value of H we can calculate the hash(GH). then we need hash(EF) which is the pair of hash(GH) to calculate their parent node — hash(EFGH). Finally, we need the hash(ABCD) to calculate the root hash — hash(ABCDEFGH).
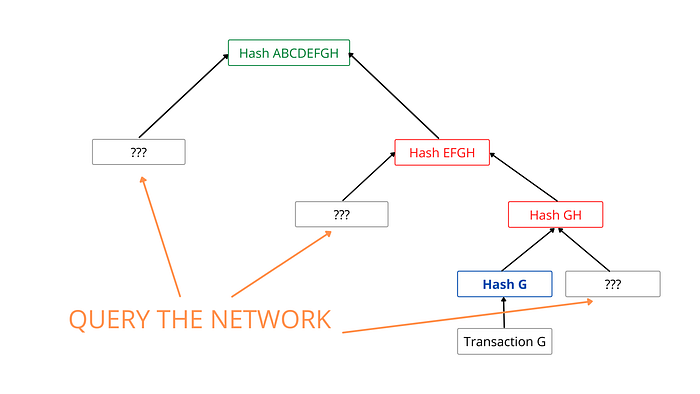
If the obtained root hash is equal to the given Merkle root hash, that means transaction G is included in the Merkle Tree. Else it is not there in the tree.
For the whole operation, we needed 3 additional hashes which we can query from the network without having to download the entire copy of the transactions. It saves space and time. The worst-case complexity for searching in the Merkle tree is O(log N).
How Merkle Tree is related to Blockchain?
Blockchain is a distributed record storing technique that is built on top of a peer-to-peer network. It is nothing but a long list of Blocks containing a bunch of information. Each block has a header and a body. The header stores the metadata (information) of the block and the body contains the actual data or transactions in the network. Learn more about blockchain while creating one yourself.
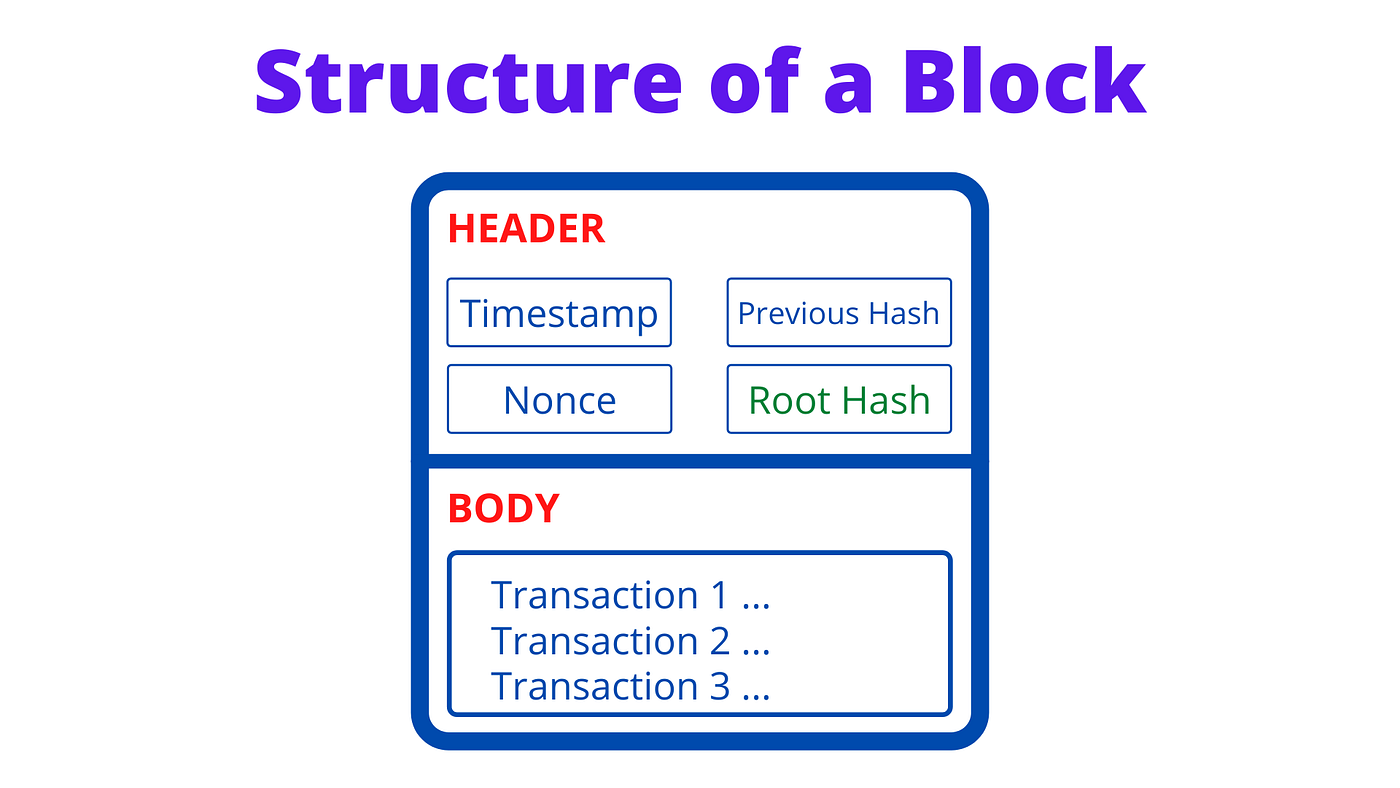
In short, a block header contains the hash value of the block, the hash value of the previous block, timestamp, a nonce (for proof-of-work), difficulty bits, version of the software, and the root hash. The root hash is the unique representation of all the transactions or data stored in that block. And it is computed using the Merkle tree — a Merkle Tree is constructed using all the transactions stored in the block and the Merkle Root is stored in the root hash field.
Role of root hash in transaction verification
The nature of blockchain requires all its peers to keep a local copy of the blockchain. For this reason, we need a mechanism to verify each transaction in a block. This is where the Merkle tree comes into play.
In a blockchain, whenever a transaction occurs between two users, it gets broadcasted to all the nodes in the network. Now all the nodes will verify the transaction and add it to their local copy of the blockchain.
If someone tries to verify the transaction, he just needs to search for the hash of the transaction in the Merkle Tree by the mechanism discussed earlier. And this searching and validating operation is performed by a special type of node in the blockchain network called Simplified Payment Verification (SPV) nodes. SPV nodes download only the block headers from the network. Using the Merkle path they can verify if a transaction is included in a block or not.
Why is the root hash so important for Blockchain?
Root hashes are important because they have certain properties that are specifically useful for the Blockchain network. Let’s see what these properties are:
- The search operations are performed on the hash values, instead of the actual data. And the hash values will change entirely, even for a slight change in the actual data. This nature of hash value helps to identify any alteration very easily.
- The search operation is very efficient. For a list of 500 transactions, we will need at most 9 hash values to validate if a transaction is present in a block or not. The worst-case complexity of the search operation is O(log N). Otherwise, we need to find linearly for the transaction which would take O(N) complexity.
- SPV nodes rely on the Merkle Tree and do the verification by downloading the block headers only. Otherwise, these nodes would have to download the entire copy of the blockchain for verification purposes. This will lead to high network traffic and requires way more storage capacity.
- The hash values also contribute to the storage and time efficiency of the Merkle Tree. Any change in a transaction will change the root hash and consequently change the hash of the block thus, breaking the entire chain coming after it.
Conclusion
The Merkle Tree proves to be an excellent choice to represent a list of data in a distributed network. The searching and data verification becomes very efficient without much storage overhead.
The full implementation of the Merkle tree with the search and verify methods is available in the repository below. And the article for creating a cryptocurrency using JavaScript is dropping soon, make sure to follow me or subscribe to get notified.
Peace & Happy Hacking!

